大規模障害事例から学ぶ(その1): GitHub (Oct, 2018)
話題となった大きなシステム障害を参考にそこから見えてくることを「他山の石」として、学んでみたいと思います。
今回は、2018年10月に発生したGitHubの障害です。 具体的な障害内容は、文末の参考リンク(記事一覧)を参照してください。
障害概要(事実ベース)
発生事象
障害の原因
- メンテナンス作業(ネットワーク機器の交換)を契機として、データベースの不整合が発生
- データベースが不整合となったのは、アメリカの東西にあるデータセンタ間の広域レプリケーションの動作についてアプリケーション層が対応できなかったため
- 復旧に時間が掛かったのは、データベースを完全復活させることを重視し数テラバイトのデータリストアに時間を要した
今後の対応策
- 広域にまたがった構成のデータレプリケーションにおいて、障害時にデータベースのマスターを広域に移動することをやめる
- サイトリライアビリティの考え方の追求
この障害から得られること(勝手なポストモーテム)
ネット上から得られる情報のみで勝手にポストモーテムを作成してみます。
教訓
- 予定しているメンテナンスこそ入念な準備と影響分析をしよう
- 広域データセンタ間での分散システムの協調障害検討を入念に!
想像する真の原因
1. ネットワーク機器の交換で発生する状況の確認漏れ
この障害の契機となったネットワーク機器交換でのネットワーク切断時間は43秒。しかし、異常を感知して「制御の切り替え」を行うツールから見ると43秒のネットワーク断は、「異常」と判断するには十分な時間である(フェールオーバが動き出すのは正しい)。
ネットワーク機器交換は、記事を見る限り予定されていた作業であるが、この構成変更作業でネットワーク断が発生することを予測していたのだろうか。以下のような点の考慮が漏れていたことが原因ではないだろうか。
- ネットワーク断を予測していた場合
- その影響範囲を明確にしていたか
- ネットワーク断を予測していなかった場合
- 変更作業のシミュレーションができていたのか
- システムの冗長性などを作業者が理解していたのか
2. データベースの広域切り替えと上位アプリケーションの連携の設計と評価の十分性
ネットワーク切断は、今回の契機以外でも発生する可能性はあった。と言うことは、上記の1. の原因より、以下の点がこの障害の一番の問題ではないかと思われる。
- 広域フェールオーバ発動のポリシー定義の妥当性
- ネットワーク障害でのデータベースの広域切り替えが及ぼすアプリケーションへの影響検討
- 広域フェールオーバでのデータベース構成の変更に対して、アプリケーションが対応できていない
3. 広域にレプリケーション配置しているデータベースのリカバリ評価を実施していなかった
ディザスタリカバリを想定して、広域にデータレプリケーションを実施している状態での、切り戻し評価が十分に実施されていたのか
障害レポートを見ると、一旦西海岸のデータセンタへ移動したデータベースを東海岸へ戻す作業に多くの時間を要している(10/22 00:41(UTC) - 10/22 16:45(UTC))。
フェールバックの作業手順(GitHub blogより)
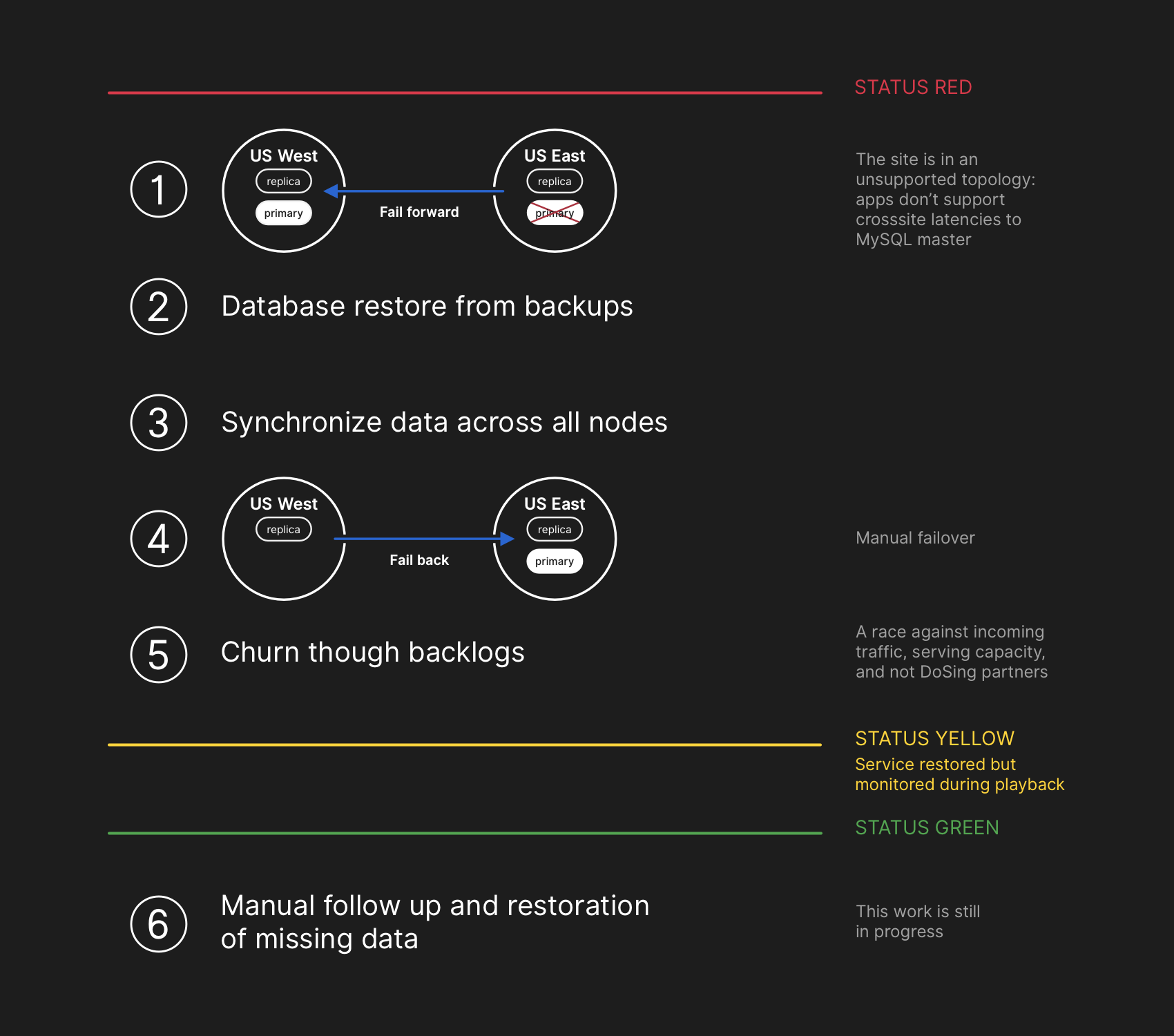
この障害が発生してから、緊急にフェールバックの検討をしているようにも見える。
SREs として考慮していくべきこと
この障害に対し、SREsとして考慮すべき点を「SRE本(サイトリライアビリティエンジニアリング―Googleの信頼性を支えるエンジニアリングチーム)」 から考えてみます。 ※章番号とタイトルは、SRE本の参照箇所です。
17.3 大規模テスト
- 17.3.1 スケーラブルなツールのテスト
- 自動化ツールを使うためのテストも実施しなければいけない
- 17.3.2 ディザスタのテスト
- 「分散システムで直面する問題の一つは、もともと結果整合性を持つ正常な挙動が、修復とうまく折り合うかを判断すること」
GutHub が上記のテストを実施しているとは思うが、組み合わせにおいて一部抜け漏れがあったのではないかと思う。これに対して、Blogでは、簡単ではないが、Chaos Engineering の検討も加えていきたいとしている。
22章 カスケード障害への対応
この障害は、影響範囲を見切れていないカスケード障害ではないか
SRE本引用:
カスケード障害を避けるためには、サービスの責任者はこの分岐点がどこにあり、そこを超えたときにシステムがどのように振る舞うべきかを理解しておかなければなりません。
SRE本では主に過負荷の事例で説明されているが、部分故障でのカスケード障害も考慮していく必要がある。
23章 クリティカルな状態の管理
GitHubでは十分に検討されていたとは思うが、この障害の根本原因はこの章の考慮が一部漏れていたのではないかと思う。
システムの状態に対する一貫性のあるビューを管理する必要が生じる
「23.1 合意を利用する目的:分散システムの協調障害」に記載されている以下がこの障害そのものを示していると思う。
障害は比較的珍しいことであり、そういった状況下にあるシステムをテストするのは、通常は行われないことです。障害発生時のシステムの挙動を説明するのはきわめて難しく、特にネットワークの分断は難題です。
23章は、内容的に難易度が高くかつ実現方法も多岐にわたるため、流し読みとなってしまうが、この障害を教訓として我々もよく理解しておくべき章であると思う。
26章 データの完全性
GitHubは、ユーザデータの保全を第一に考えて、データベースの再構築を実施した、とBlogに記載されている。Gitリポジトリを提供しているサービス企業として、明確にポリシーを示しており共感できる。 Githubでは、この章の「データ完全性」は特に留意して実施しているものと思われるが、今回の障害で少しであるが、リストアできなかったデータがあったことを公表している。さらに約1日リポジトリにアクセスできなかった点は、開発者からすると可用性観点ではギリギリの状況だったと思う。 26章に記載されている通り、データの完全性とサービスの再開の時期はよく検討しないと顧客は他のサービスへ移ってしまう可能性もある。
GitHub Blog で、サイトリライアビリティの考え方が変わった、とあります。 広域なデータセンタでの分散協調を行うのは、様々な考慮が必要になってきます。コトが起こった時に、目をつぶってうまく動いてくれ!と祈るだけではダメでしょう。絶対大丈夫、と言う確信を保つために、定期的なディザスタリカバリのテスト実施と、「壊れても」継続性を維持する堅牢性技術を(予算の許す限り)取り組みたいところです。
記事一覧
- 2018.10.22 ITMedia: GitHubがダウン 「データストレージシステムに障害」
- 2018.10.22 まとめ特ダネ: GitHubが世界中で障害「GitHubが落ちてるから仕事にならない(と言って休もう)」
- 2018.10.23 マイナビ: GitHub、全世界で長時間ダウン - 今は復旧
- 2018.10.23 個人: GitHubのストレージ障害
- 2018.10.26 財経新聞: GitHubの障害、完全復旧までに24時間かかる
- 2018.10.31 @IT:GitHubが障害を総括、43秒間のネットワーク断が1日のサービス障害につながった
- 2018.10.30 Github blog: October 21 post-incident analysis
- 2018.11.04 アルマサーチ: 2018年10月22日23日におこったGitHubの障害から考える
- 2018.11.07 byond: GitHub(ギットハブ)また障害か 更新・保存できないなど不具合報告相次ぐ